

AI×MES智能協(xié)同革新
不只是秒答,更是顛覆
你是否也在經(jīng)歷這些問題:
-
問題反饋效率低
一線員工在使用系統(tǒng)時遇到異常
,需要層層反饋、溝通繁瑣,問題閉環(huán)周期過長。-
項目進度追蹤滯后
項目執(zhí)行依賴微信群和Excel表
,計劃延誤時無人察覺、責任難追。-
數(shù)據(jù)看不懂、系統(tǒng)查不出
MES 雖然接入了生產(chǎn)數(shù)據(jù),但查起來復雜
,表格沒有結(jié)論、圖表沒有重點。一鍵升級的解決方案
| 當前痛點 | 智能升級方案 |
| 統(tǒng)問題多、溝通低效 | AI 智能體 7×24在線,直接秒答 |
| 項目進度跟不上 | 低代碼平臺+ 大模型,自動生成甘特圖與報表 |
| 查數(shù)據(jù)難、出報表慢 | 提問即得,無需學習復雜系統(tǒng) |
功能1:配變項目問題查詢
只需一句描述: “干變產(chǎn)線 A 工位控制臺報錯”
功能2:項目進度智能分析
輸入:“A305箱變的組裝進度怎么樣
真實場景舉例:
張家港開關(guān)柜項目生產(chǎn)主管只需在AI界面輸入“高低壓柜 X12 當前狀態(tài)”
,即可快速定位到當前工序、負責人、完成率,實時調(diào)度,無需等待日報或主管反饋。低代碼平臺知識庫文檔撰寫規(guī)范
傳統(tǒng)方式:將整份參考文件(或長段文字)直接放入系統(tǒng),內(nèi)容冗長且結(jié)構(gòu)混亂。
創(chuàng)新方式:在錄入前
,將文件進行整理,梳理層級結(jié)構(gòu),適合分段解析、精準召回。| 項目 | 規(guī)范要求 | 示例 / 建議 |
| 文件格式 | 建議使用 .md 、 .txt ;其中 Markdown 最佳 | project-intro.md |
| 標題結(jié)構(gòu) | 遵循標準 Markdown 標題層級,清晰分章分節(jié) |
# 一級標題 ## 二級標題 ### 三級標題 |
| 段落長度 | 單段文字建議 300~500 字以內(nèi),避免超長文本 | 將一個長段內(nèi)容拆分為 2~3 段 |
| 內(nèi)容組織 | 結(jié)構(gòu)清晰,邏輯性強,避免內(nèi)容過度重復或無序 | 建議按「項目介紹 → 架構(gòu)設計 → 技術(shù)實現(xiàn)」等順序分層 |
| 問答結(jié)構(gòu) | 采用 FAQ 形式,每個問題單獨成段,便于精準檢索 | ## 什么是低代碼平臺?低代碼平臺是一個…… |
| 語義完整性 | 保持每節(jié)內(nèi)容自洽,不跨段依賴或頻繁引用 上下文 | 如「用戶權(quán)限管理」單獨成節(jié), 討論管理方式和應用場景 |
| 表格/圖表處理 | 表格推薦使用 Markdown 語法;圖表盡量轉(zhuǎn) 為文字描述 ,避免插入復雜圖片 |
使用簡單 Markdown 表格,如下 例中的寫法 |
| 排版簡潔 | 避免過多樣式(顏色 、加粗 、嵌套表格), 以便機器解析 |
保持 Markdown 純凈結(jié)構(gòu) ;必要 時可用簡單的列表或引用 |
| 編碼格式 | 文件需使用 UTF-8 編碼,避免亂碼 | 保存為 UTF-8 格式 ,尤其是 .txt文件 |
| 文件大小 | 單文件建議 < 5MB ;過大的文件可以拆分多 個部分上傳 |
大于 100 頁的 PDF 可根據(jù)章節(jié)或 模塊進行拆分 |
提示詞工程-"用AI馴服AI"
傳統(tǒng)方式:人工編寫提示詞(Prompt) → 輸出結(jié)果不穩(wěn)定
創(chuàng)新方案: 用AI馴服AI,將我們的簡單的需求發(fā)給AI
指令對比:
-
優(yōu)化前的提示詞
|
## 任務 根據(jù)用戶輸入的內(nèi)容提取項目簡稱 ,不需要額外加任何符號
|
-
優(yōu)化后的提示詞(需要修改)
|
# Role - **You are**: 一個智能文本匹配助手,能夠基于知識庫檢索用戶輸入的內(nèi)容 ,并返回對應的 項目簡稱 。
- **Skills**: - 知識庫檢索 & 模糊匹配 - 語義分析 & 關(guān)鍵詞提取 - 高效精準匹配 # Output Requirements: - **只返回項目簡稱**,不包含任何額外字符 、標點 、說明或格式化標記。
- **優(yōu)先匹配“項目簡稱”**:若用戶輸入與知識庫中的 "項目簡稱" 相同或相似 ,直接返回該簡 稱 。
- **若找不到簡稱,則匹配“項目名稱”**: - 檢索知識庫 ,找出最接近的 "項目名稱" 。
- 若找到匹配項,返回對應的 "項目簡稱" 。
- **無匹配時返回**: `找不到該項目` ,不猜測 、不生成無關(guān)內(nèi)容。
- **支持模糊匹配**:允許輸入部分簡稱或項目名稱的關(guān)鍵詞 ,尋找最相關(guān)的匹配項 。
# Example Inputs & Outputs: **Input:** `三峽雄安能源江蘇張家港光束汽車` **Return:** 三峽雄安 **Input:** `張家港光束汽車` **Return:** 三峽雄安 **Input:** `南方電網(wǎng)廣州供電局` **Return:** 找不到該項目 |
效果對比:
× 優(yōu)化前的效果:
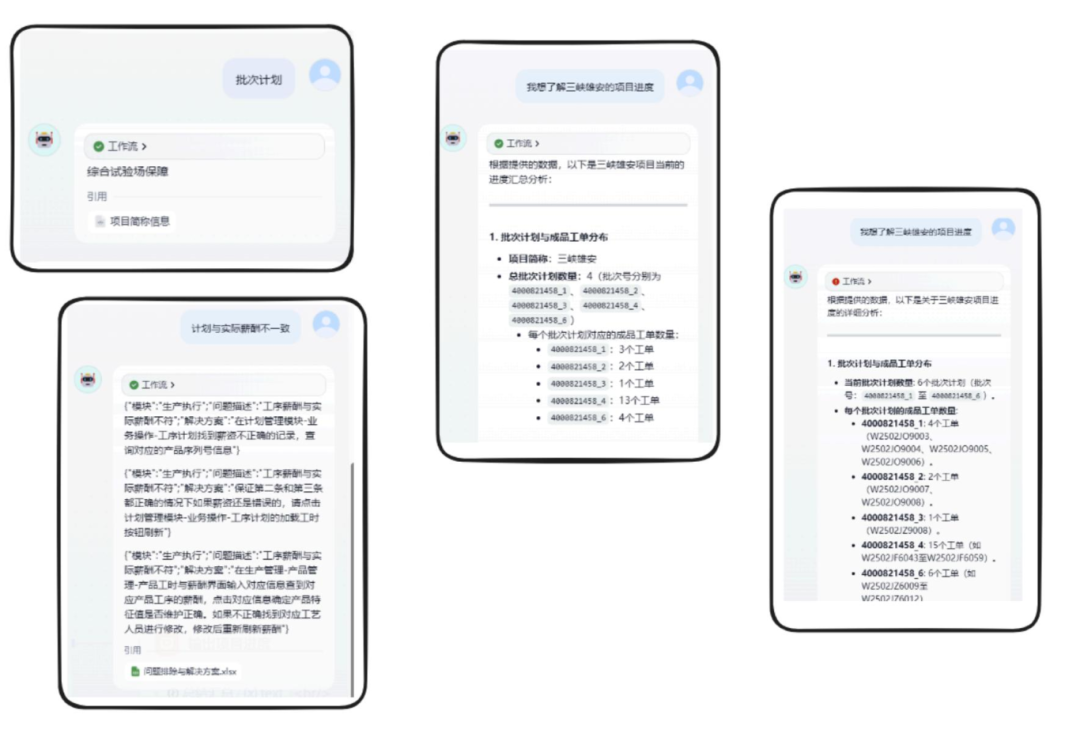
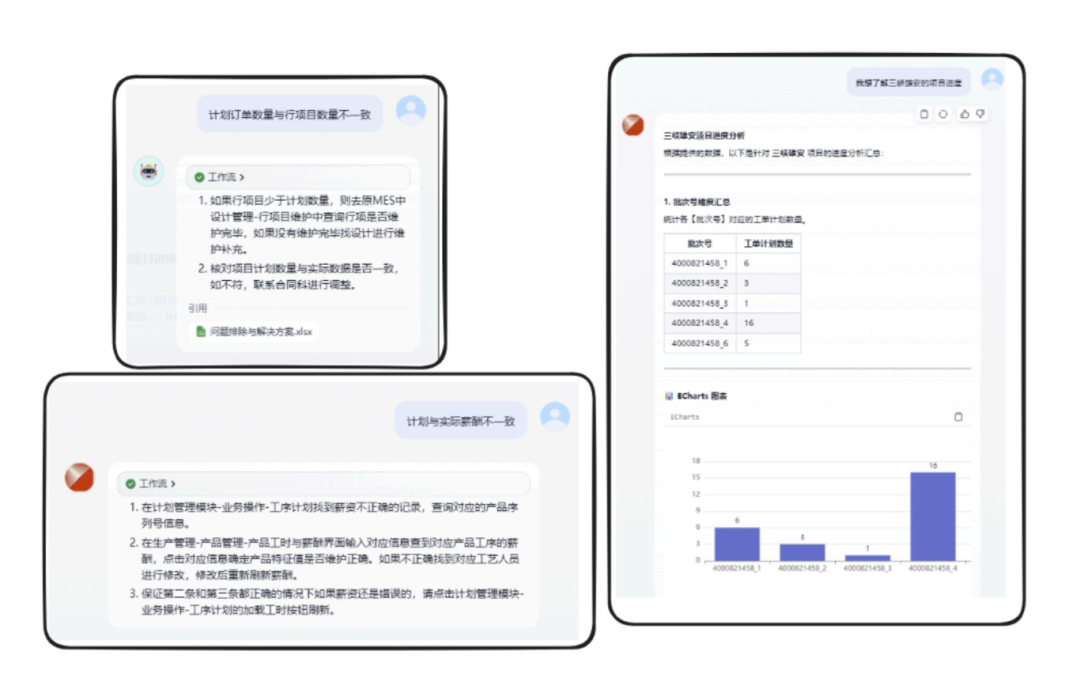
√ 優(yōu)化后的效果:
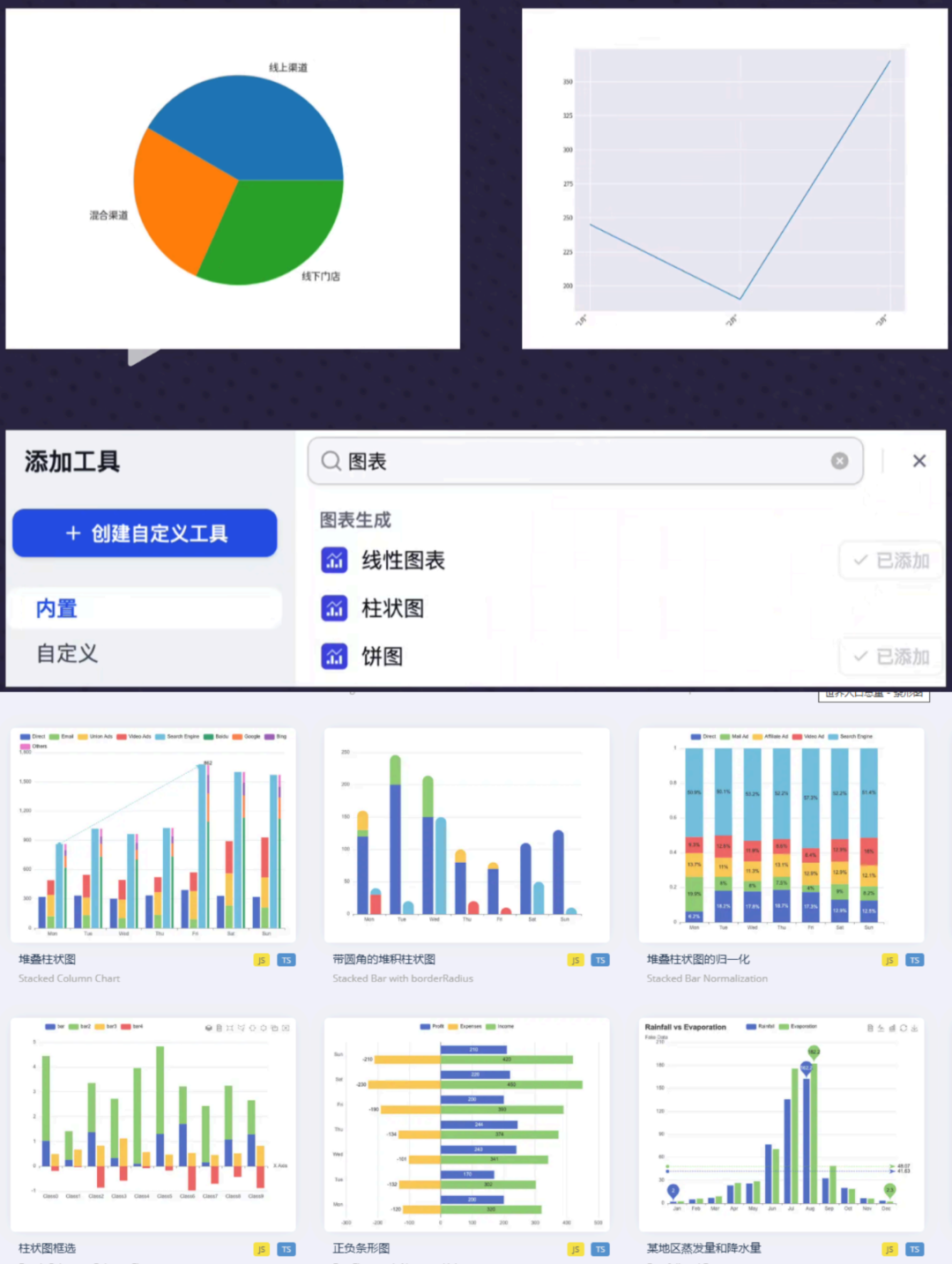
傳統(tǒng)方式:使用低代碼平臺的插件輸出簡單的圖表
,圖表類型少,樣式單一創(chuàng)新方案:
1. 利用低代碼平臺內(nèi)置的echarts塊,輸出符合自己需求的echarts圖表
2. 參考鏈接(ecahrts官網(wǎng)): https://echarts.apache.org/examples/zh/index.html
效果對比:(兩張圖進行效果對比)
核心代碼:
|
echarts { "xAxis": { "type": "category", "data": ["高風險", "中風險", "低風險"] }, "yAxis": { "type": "value" }, "series": [ { "data": {{ 風險評估_數(shù)據(jù) }}, "type": "bar", "label": { "show": true, "position": "top" } }] } |
使用方法:
-
利用代碼輸出echarts配置項
|
import json def main(csv_data): """ 解析輸入的 CSV 字符串數(shù)據(jù) ,提取“模塊名稱”和“數(shù)量”,構(gòu)造用于 ECharts 的配置(柱 狀圖)。
輸入數(shù)據(jù)可以是每條記錄單獨一行 ,也可以是所有記錄在一行中 ,每兩個字段為一組。
""" # 先嘗試按行分割 lines = csv_data.strip().splitlines() records = [] if len(lines) == 1 and csv_data.find('\n') == -1: # 如果沒有換行符 ,假設數(shù)據(jù)是逗號分隔的 ,每兩個字段為一組
parts = csv_data.strip().split(',') if len(parts) % 2 != 0: return {'output': 'Error: 數(shù)據(jù)格式錯誤,每組應該有兩個字段 '} for i in range(0, len(parts), 2): record = (parts[i].strip(), parts[i+1].strip()) records.append(record) else: # 否則按行讀取 ,每行數(shù)據(jù)應包含兩個字段
for line in lines: parts = line.split(',') if len(parts) < 2: return {'output': 'Error: 每行數(shù)據(jù)格式錯誤 ,必須包含模塊名稱和
數(shù)量 '} records.append((parts[0].strip(), parts[1].strip())) categories = [] values = [] for category, value_str in records: try: value = float(value_str) except Exception as e: return {'output': f"Error: 數(shù)量字段轉(zhuǎn)換失敗 - {value_str}"} categories.append(category) values.append(value) # 構(gòu)建 ECharts 配置 echarts_config = { "xAxis": { "type": "category", "data": categories }, "yAxis": { "type": "value" }, "series": [ { "name": "數(shù)量", "type": "bar", "data": values } ] } # 生成輸出文件 output = "```echarts\n" + json.dumps(echarts_config, indent=2, ensure_ascii=False) + "\n```" return {"output":output} |
-
利用指令讓大模型自動生成
|
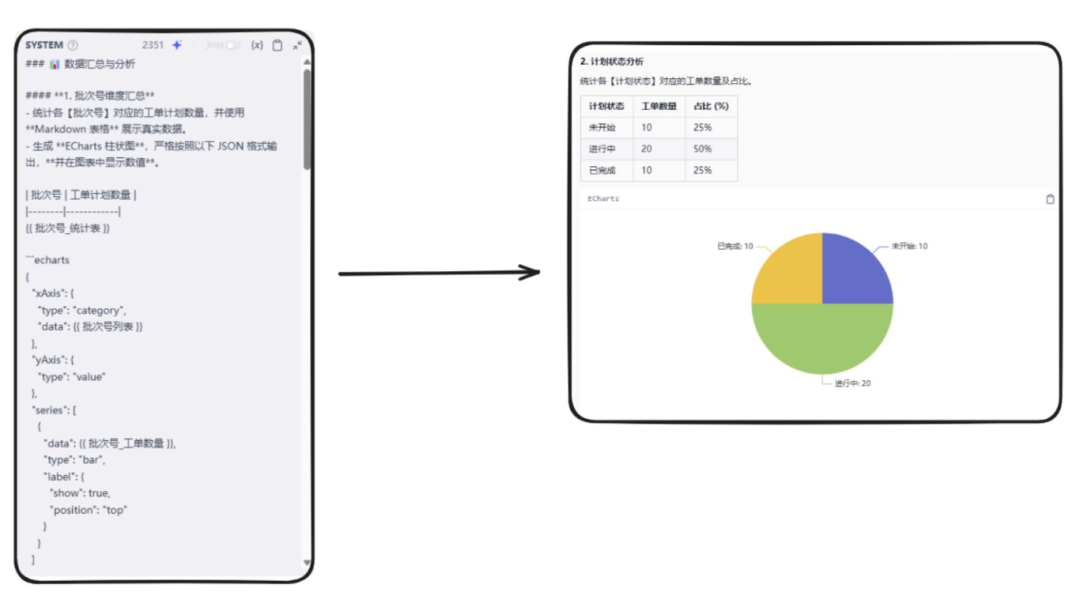
###數(shù)據(jù)匯總與分析 #### **1 .批次號維度匯總** - 統(tǒng)計各【批次號】對應的工單計劃數(shù)量,并使用 **Markdown 表格** 展示真實數(shù)據(jù) 。
- 生成 **ECharts 柱狀圖** ,嚴格按照以下 JSON 格式輸出,**并在圖表中顯示數(shù)值** 。
| 批次號 | 工單計劃數(shù)量 | |-------- |------------ | {{ 批次號_統(tǒng)計表 }} ```echarts { "xAxis": { "type": "category", "data": {{ 批次號列表 }} }, "yAxis": { "type": "value" }, "series": [ { "data": {{ 批次號_工單數(shù)量 }}, "type": "bar", "label": { "show": true, "position": "top" } } ] } ` ` ` ### **輸出要求** - **所有數(shù)據(jù)必須以 Markdown 表格格式呈現(xiàn) ,數(shù)據(jù)必須是真實的 ,不得使用示例數(shù)據(jù) 。**
- **Markdown 表格必須直接輸出 ,不應嵌套在代碼塊或 JSON 字符串中 。**
- **所有可視化數(shù)據(jù)必須嚴格按照指定的 ECharts JSON 格式輸出 ,確保 低代碼平臺 識別并 生成圖表 。**
- **所有圖表必須在數(shù)據(jù)點上顯示數(shù)值 , ECharts 配置需包含 ` "label " : { " show " : true } ` 。**
- **不得省略任何 JSON 結(jié)構(gòu) ,變量部分必須替換為真實數(shù)據(jù) 。**
- **Markdown 表格與 ECharts 數(shù)據(jù)應匹配 ,避免數(shù)據(jù)不一致的問題 。**
{{#context#}} |
1. 效率躍升:響應時間從小時級→分鐘級
2. 數(shù)據(jù)聯(lián)通:支持多系統(tǒng)集成(MES
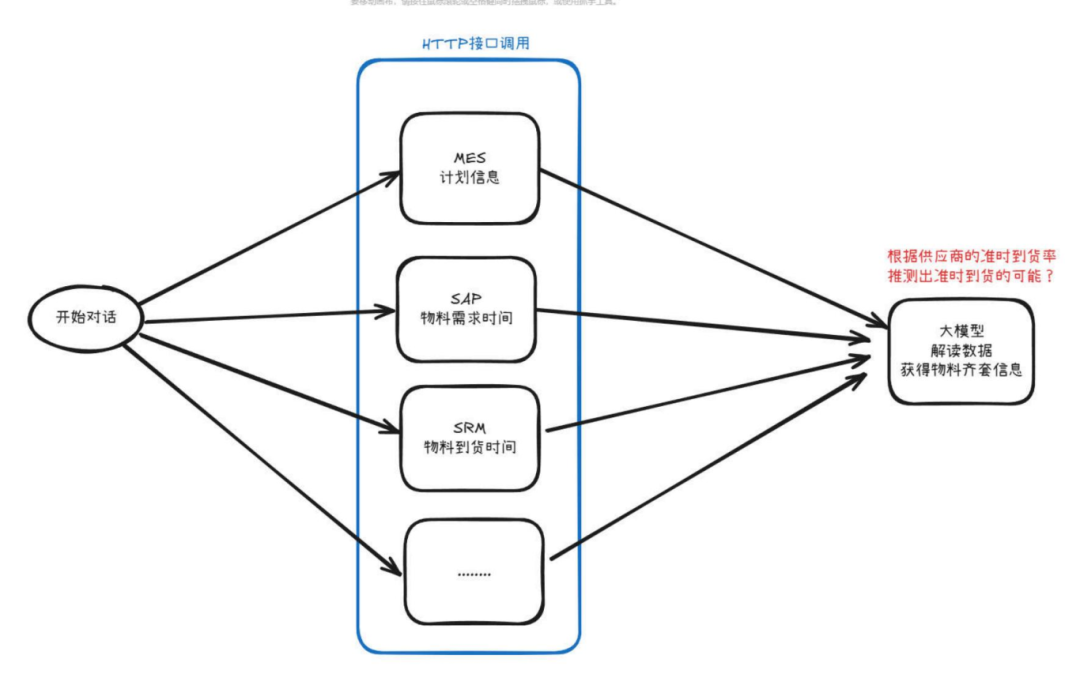
3. 智能診斷:基于系統(tǒng)數(shù)據(jù)

4. 動態(tài)可視化:可快速的輸出圖表
5. 語義理解能力:即使描述的問題和知識庫中的標題不一樣
| 特性 | AI語義查詢 | 傳統(tǒng)數(shù)據(jù)庫查詢 |
| 語義模糊容忍 | 是 | 否 |
| 拼寫錯誤容忍 | 是(輕度) | 否 |
| 語義上下文理解 | 有 | 無 |
| 查詢語言要求 | 自然語 | 嚴格語法 |
| 學習能力 | 可以不斷訓練優(yōu)化 | 固定邏輯 |
| 場景方向 | 應用說明 |
| 問題知識庫 | 自動沉淀開關(guān)柜/箱變項目常見異常,如接線不符 、元件漏裝等 |
| 工單進度分析 | 查詢每臺箱變當前進度 、滯后原因、責任工位 |
| 齊套檢查 | 判斷變壓器是否具備開工條件 ,物料是否齊套 ,提前發(fā)出缺料預警 |
| 智能報表 | 每日產(chǎn)線產(chǎn)出統(tǒng)計、不合格項趨勢 、 BOM匹配異常統(tǒng)計圖表 |
| 決策支持 | 基于歷史項目數(shù)據(jù) ,智能分析工序瓶頸和調(diào)度建議 |
不管你是干配電、箱變
-
讓問題閉環(huán)更快
-
讓管理更透明
-
讓知識不再依賴“老員工”
現(xiàn)在就是啟動智能協(xié)同的最好時機!
歡迎留言交流
深思AI(1):從“人找數(shù)據(jù)”到“數(shù)據(jù)找人”:MOM系統(tǒng)如何用AI重構(gòu)生產(chǎn)決策邏輯?
深思AI(2):漢思AI視覺識別項目突破 深思AI(4):漢思信息MES/MOM全面接入DeepSeek,深思(ThinkDeep)V2.0助推企業(yè)進入AI+智造階段 HanThink 漢思信息技術(shù)有限公司成立于2008年 目前服務的領(lǐng)域涵蓋離散和流程兩大行業(yè):汽車行業(yè) 尤其在汽車、醫(yī)藥、食品、新能源行業(yè)(新能源汽車、光伏、電池、儲能等)積累了豐富的實施經(jīng)驗和行業(yè)方案,是國內(nèi)MOM的領(lǐng)先供應商。 掃碼關(guān)注“漢思” 識別二維碼 即可關(guān)注 如有侵權(quán),請聯(lián)系漢思刪帖

漢思信息公眾號

掃碼關(guān)注漢思信息公眾號
其他原創(chuàng)




